The Datawarehouse Tables --- Dimension and Fact Tables
In last post we discussed about the Architecture of Datawarehouse and also discussed about the Staging Area in detail.
Let us talk about the various types of tables present in a Datawarehouse.
As discussed earlier: Datawarehouse is combination of multiple tables which are linked to each other. These multiple tables which we are talking about are Dimension table and Fact Table.
Consider a simple Datawarehouse structure below:
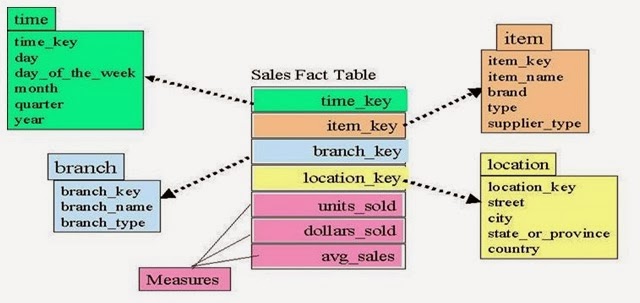
Fig: Schema
Dimension Tables: The subject oriented tables which we discussed earlier in the definition of Datawarehouse are usually the Dimension tables. The Dimension tables are the Master tables(Usually). Dimension tables are used to describe a particular entity (dimensions); they contain dimension keys, values and attributes.
Dimension tables usually describe a particular aspect of a business, like EMPLOYEE, CUSTOMERS, AGENTS, LOCATIONS etc.
Dimension table contains columns like EMPLOYEE_ID, EMPLOYEE_NAME, EMPLOYEE_LOCATION, AGE, GENDER etc. Dimension table contains data with Numeric as well as text data.
Consider an example of an EMPLOYEE table in a Datawarehouse.
The typical column names in an Employee table will be: Employee_ID(Number), Employee_Name(String), Employee_Age(Number), Employee_Address(String) etc.
Typical characteristics of a Dimension table:
-- rows with lots of descriptive text along with numbers - Dimension table contains data with Numeric as well as text datatypes. Like AGE column is Number and NAME, ADDRESS column is text data. Mostly Small tables (few thousands of records) - Dimension tables usually contain less number of records. Dimension tables are typically small, ranging from a few to several thousand rows.
--Consider LOCATION table, a business usually don't have many locations. Location count can be in 100's or 1000's. Similarly, EMPLOYEES table, a business can have employees in the range of lakh's, which is not a very big number for Data Warehouse.
--Occasionally dimensions can grow fairly large, however. For example, a large credit card company could have a customer dimension with millions of rows.
--Joined to fact table by foreign keys - As discussed earlier in the blog of Schema's, all Dimension table have their Primary Key's present in Fact Table as Foreign Key's for reference purpose.
--Heavily indexed - Dimension tables can have many indexes defined on them. For Example Primary Key, Foreign Key, NOT NULL, Unique etc.
--Can be normalized
Typical dimensions
Date, Region (Country, Cities), Products, Customers, Salesperson, Employees etc.
In the Diagram above: Time, Item, Location Branch are the Dimension table.
Fact Table: A fact table is a table that contains the Calculated/measured/Factual value - called as MEASURES. Fact tables are loaded using the values in the Dimension table. For example, avg_sales in the above diagram would be such a measure. This measure is stored in the fact table with the appropriate granularity. For example, it can be sales amount by store by day. In this case, the fact table would contain three columns: A date column, a store column, and a sales amount column.
Fact tables contain keys to dimension tables as well as measurable facts that data analysts would want to examine.
Fact tables can grow very large, with millions or even billions of rows. It is important to identify the lowest level of facts that makes sense to analyze for your business this is often referred to as fact table "grain".
Consider a scenario, utilizing the diagram above
Time_key = 111
Item_key = 11
Branch_key = 1111
Location_key = 1001
An item with Item_key = 11, sold from branch with branch_key = 1111 at Location from Location_key=1001 at a time with Time_key=111 is sold for $50, i.e,
11 * 1111 * 1001 * 111 = $50.
Now, 11, 1111, 1001, 111 would be stored in the respective Dimension table and the calculated value $50 would be stored in the Fact table. Also it is said that the product has been sold for 5 times, which will be present in the Fact table.
The structure of Fact table will be:

As explained above we can have large number of such calculations.
Hope you are clear about the Dimension and Fact table.
Some definitions related to Tables:
Attribute: A unique level within a dimension. These are nothing but the column names of the tables. For example, Month is an attribute in the Time Dimension.
Hierarchy: The specification of levels that represents relationship between different attributes within a dimension. For example, one possible hierarchy in the Time dimension is Year → Quarter → Month → Day.
Types of Fact Tables:
There are two types of Fact tables:
Cumulative: This type of fact table describes what has happened over a period of time. For example, this fact table may describe the total sales by product by store by day. The facts for this type of fact tables are mostly additive facts. The first example presented here is a cumulative fact table.
Snapshot: This type of fact table describes the state of things in a particular instance of time, and usually includes more semi-additive and non-additive facts. The second example presented here is a snapshot fact table.
Types of Facts
There are three types of facts:
Additive: Additive facts are facts that can be summed up through all of the dimensions in the fact table.
Semi-Additive: Semi-additive facts are facts that can be summed up for some of the dimensions in the fact table, but not the others.
Non-Additive: Non-additive facts are facts that cannot be summed up for any of the dimensions present in the fact table.
Let us use examples to illustrate each of the three types of facts. The first
example assumes that we are a retailer, and we have a fact table with the
following columns(This mean we have 3 Dimension tables each containing
one primary key that is present as foreign key in fact table, as shown below):
Sales_Amount is the Measure in the Fact Table.
| Date_ID |
| Store_ID |
| Product_ID |
| Sales_Amount |
Consider values present in Dimension table:
Date Dimension Table:
Date_ID, DATE
1,01-01-2015
2,02-01-2015
3,03-01,2015
4,04-01-2015
Store Dimension Table:
Store_ID, Store_Location
101,India
102,Germany
103,China
104,Japan
Product Dimension Table:
Product_ID,Product_Name
10,RICE
20,SUGAR
30,BREAD
40,WHEAT
The purpose of this table is to record the sales amount for each product (Product_ID) in each store (Store_ID) on a daily basis(Date_ID).
In this case, Sales_Amount is an additive fact, because Sales_Amount can be calculated using the values of all the 3 KEYS present in the Dimension tables, i.e, DATE_ID, Store_ID and Product_ID.
So, Sales_Amount for 01-01-2015(DATE_ID=1) in India (Store_is=101) for RICE (Product_ID=10), is $100. $100 here is Sales_Amount present in Fact table which is calculated using all 3 three dimension tables values, hence is called Additive Fact.
Let's take next example:Say we are a bank with the following fact table:
| Date |
| Account |
| Current_Balance |
| Profit_Margin |
The purpose of this table is to record the current balance for each account at the end of each day, as well as the profit margin for each account for each day. Current_Balance and Profit_Margin are the Measure's.
Current_Balance is a semi-additive fact, as it makes sense to add them up for all accounts (what's the total current balance for all accounts in the bank?), but it does not make sense to add them up through time (adding up all current balances for a given account for each day of the month does not give us any useful information).
Profit_Margin is a non-additive fact, for it does not make sense to add them up for the account level or the day level.
In the next post we will talk about the different types of Schema's. Another very important concept.